들어가기 앞서…
병렬 처리가 되지 않는 server action 도 읽어보자.
개인 블로그를 팀 블로그 서비스로 변환하고 있는데 개발이 어느정도 마무리되고 있어서, 미뤄뒀던 페이지 로딩 속도 향상을 시도했다.
이 과정에서 prefetchQuery, useQuery, useSuspenseQuery에 대해 자세히 찾아보면서 waterfall에 대해서도 고민해 보았다.

문제 원인 분석
- useSuspenseQuery
- Nested Component Waterfall
- 부가적인 설정 (Vercel 리전 위치 + Supabase query Index)
문제 해결
Vercel 리전 위치
다른 부가적인 원인을 해결하기 전에 먼저 살펴보면 좋다.
vercel은 serverless function에 대해 아래와 같이 설명하고 있다.
By default, Serverless Functions execute in Washington, D.C., USA (
iad1) for all new projects to ensure they are located close to most external data sources, which are hosted on the East Coast of the USA. You can set a new default region through your project's settings on Vercel
기본 위치가 Washington, D.C., USA이기 때문에 본인의 위치와 가장 근접한 리전으로만 바꿔줘도 latency가 크게 줄어든다.
NextJS 기준으로 vercel.json을 추가한다.
// app router(no src): app과 동일한 레벨
// app router(src): src와 동일한 레벨
{
"regions": ["icn1"]
}Supabase Query Index
supabase는 index를 아래와 같이 설명하고 있다.
An index makes your Postgres queries faster. The index is like a “table of contents” for your data — a reference list which allows queries to quickly locate a row in a given table without needing to scan the entire table (which in large tables can take a long time).
인덱스는 ‘목차’와 같은 것으로, 쿼리가 전체 테이블을 스캔할 필요 없이 특정 테이블에서 행을 빠르게 찾을 수 있게 해주는 참조 목록이다. 테이블에 대한 동작 속도를 높여주는 일종의 자료구조인 것 같다.
supabase 프로젝트의 Query Performance에서 아래 항목을 참고해서 Index를 설정하면 된다.
- Most time consuming
- Slowest execution
- Total time latency
(또는, Performance Advisor에서 각 테이블 별로 추천하는 Index 참고)
Request Waterfall을 야기하는 useSuspenseQuery 변경
useSuspenseQuery는 작업이 끝날 때 까지 다른 작업을 blocking 한다. 즉, request waterfall을 야기한다.
function App () {
// 다음 3개의 쿼리는 순차적으로 실행된다.
const usersQuery = useSuspenseQuery({ queryKey: ['users'], queryFn: fetchUsers })
const teamsQuery = useSuspenseQuery({ queryKey: ['teams'], queryFn: fetchTeams })
const projectsQuery = useSuspenseQuery({ queryKey: ['projects'], queryFn: fetchProjects })
...
}위 코드에서 각 query가 끝나기 전까지 다른 query는 blocking 된다.(usersQuery -> teamsQuery -> projectesQuery 순으로 순차적으로 실행된다.)
useSuspenseQuery를 제거하기 보다는 목적에 맞게 여러 방법을 사용해서 개선해 볼 수 있다.
위 코드는 useSuspenseQuries를 사용해서 waterfall을 개선할 수 있다.
const [usersQuery, teamsQuery, projectsQuery] = useSuspenseQueries({
queries: [
{ queryKey: ['users'], queryFn: fetchUsers },
{ queryKey: ['teams'], queryFn: fetchTeams },
{ queryKey: ['projects'], queryFn: fetchProjects },
],
})다른 방법으로는 useSuspenseQuery를 모두 useQuery로 변경하는 것이다.
useQuery로 변경하게 되면 각 쿼리는 병렬(parallel)로 실행된다.
아래는 실제 서비스의 코드에서 useSuspenseQuery와 useQuery의 비교이다.


(처음에는 useQuery를 사용하면 로딩 상태를 선언적으로 처리(<Suspense> 이용)할 수 없기 때문에 무조건 useSuspenseQuery를 사용했었는데, waterfall을 야기할 수 있기 때문에 목적과 필요성에 맞게 사용하면 될 것 같다.)
Nested Component waterfall 개선 ( + 실제 예시)
이는 아래와 같은 구조에서 발생한다.
function Article({ id }) {
const { data: articleData, isPending } = useQuery({
queryKey: ['article', id],
queryFn: getArticleById,
})
if (isPending) {
return 'Loading article...'
}
return (
<>
<ArticleHeader articleData={articleData} />
<ArticleBody articleData={articleData} />
<Comments id={id} />
</>
)
}
function Comments({ id }) {
const { data, isPending } = useQuery({
queryKey: ['article-comments', id],
queryFn: getArticleCommentsById,
})
...
}Article과 Comments 컴포넌트 모두 id를 props로 받아서 useQuery를 실행한다. 하지만 위 구조에서는 getARticleById 가 실행되고 완료되기 전까지 getArticleCommentsById 가 실행되지 않는다. 즉 두 useQuery가 serial하게 실행되어 waterfall을 야기한다.
하지만, id props는 Article 컴포넌트에서 바로 사용이 가능하기에 굳이 Comments에 넘겨서 serial하게 실행될 필요가 없다.
그래서, 다음과 같은 구조로 개선할 수 있다.
function Article({ id }) {
const { data: articleData, isPending: articlePending } = useQuery({
queryKey: ['article', id],
queryFn: getArticleById,
})
const { data: commentsData, isPending: commentsPending } = useQuery({
queryKey: ['article-comments', id],
queryFn: getArticleCommentsById,
})
if (articlePending) {
return 'Loading article...'
}
return (
<>
<ArticleHeader articleData={articleData} />
<ArticleBody articleData={articleData} />
{commentsPending ? (
'Loading comments...'
) : (
<Comments commentsData={commentsData} />
)}
</>
)
}Article 컴포넌트에서 getArticleById, getArticleCommentsById 를 parallel하게 실행하여 waterfall을 개선했다.
😀 실제 코드 예시
기존 supabase의 Table 구조에 따라서, metadata와 footer의 데이터는 blogData에 포함된 metadata_id, footer_id로 접근했었다.
// 모든 커스텀 훅은 useQuery를 사용했음
export default function RootSettingSection({ teamName }: { teamName: string }) {
const { data: blogData } = useQueryTeamInfo({ name: teamName });
return (
<div className="flex flex-col gap-7">
<main className="grid grid-cols-2 grid-rows-[auto_auto_auto] gap-6">
{blogData &&
<>
<BlogSettingSection blogData={blogData} />
<MetadataSection metadata_id={blogData.metadata_id} />
<FooterSection footer_id={blogData.footer_id} />
</>
}
</main>
</div>
);
}
export default function MetadataSection({ metadata_id }: { metadata_id: string }) {
const { data: metaData } = useQueryGetMetadata({ id: metadata_id });
return ...
}
export default function FooterSection({ footer_id }: { footer_id: string }) {
const { data: footerData } = useQueryGetFooter({ id: footer_id });
return ...
}앞서 언급했던 Nested Component 구조로 인해 아래의 request waterfall구조를 갖는다.
1. |> getTeamInfo()
2. |> getMetadataInfo()
3. |> getFooterInfo()그래서 metadata와 footer의 데이터를 teamName 으로 접근할 수 있도록 Table 구조를 변경하여 다음과 같이 개선했다.
// 이제 모든 useQuery는 teamName으로 접근한다.
export default function RootSettingSection({ teamName }: { teamName: string }) {
const { data: blogData } = useQueryTeamInfo({ name: teamName });
const { data: metaData } = useQueryGetMetadata({ team_name: teamName });
const { data: footerData } = useQueryGetFooter({ team_name: teamName });
return (
<div className="flex flex-col gap-7">
<main className="grid grid-cols-2 grid-rows-[auto_auto_auto] gap-6">
{blogData && <BlogSettingSection blogData={blogData} />}
{metaData && <MetadataSection metaData={metaData} />}
{footerData && <FooterSection footerData={footerData} />}
</main>
</div>
);
}각각의 하위 컴포넌트(MetadataSection, FooterSection)에서 useQuery를 실행하는 대신 상위의 RootSettingSection에서 parallel하게 실행되도록 변경되어서 waterfall이 개선됐다.
정리하면, 아래의 request waterfall 구조를 갖게 된다.
1. |> getTeamInfo()
1. |> getMetadataInfo()
1. |> getFooterInfo()prefetchQuery 그리고 fetchQuery 사용
두 함수 모두 사전에 쿼리를 호출하는 역할을 수행한다.
fetchQuery는 data, error를 반환하며 error 핸들링이 필요할 때 사용한다. prefetchQuery는 반환값이 없다.
prefetchQuery는 데이터를 미리 요청하여 캐시에 저장해둔다. 이를 통해 보다 빠르게 페이지를 보여줄 수 있다.
또한, 클라이언트 컴포넌트에서 prefetchQuery와 동일한 쿼리를 useQuery를 사용하여 실행했을 때, 실제 네트워크 요청을 보내지 않고 서버에서 전달받은 쿼리 캐시를 사용한다는 이점이 있다.
다음은 앞선 예시에서 사용된 RootSettingSection을 보여주는 페이지(라우트)이다. RootSettingSection에서 실행하는 두 개의 useQuery를 prefetch하고 있다.
// RootSettingSection을 보여주는 page.tsx (/setting)
// HydrationBoundary는 layout.tsx에서 처리
import React from "react";
import RootSettingSection from "../../../../components/RootSettingSection";
import { prefetchMetadata } from "../../../../hooks/query/team/useQueryGetMetadata";
import { prefetchFooter } from "../../../../hooks/query/team/useQueryGetFooter";
export default async function SettingPage({
params,
}: {
params: { teamName: string };
}) {
const { teamName } = params;
await prefetchMetadata({ team_name: teamName });
await prefetchFooter({ team_name: teamName });
return <RootSettingSection teamName={teamName} />;
}
export const prefetchMetadata = async ({ team_name }: GetMetadataParam) => {
const queryClient = getQueryClient();
await queryClient.prefetchQuery({
queryKey: ["metadata", team_name],
queryFn: () => getMetadata({ team_name }),
});
};
// ... prefetchFooter()도 동일SSR에서 prefetch를 했기 때문에 RootSettingSection 컴포넌트에서useQueryGetMetadata, useQueryGetFooter 는 중복 요청없이 데이터를 사용할 수 있다.
// RootSettingSection.tsx
"use client";
import React from "react";
import BlogSettingSection from "./BlogSettingSection";
import MetadataSection from "./MetadataSection";
import FooterSection from "./FooterSection";
import { useQueryTeamInfo } from "../hooks/query/team/useQueryTeamInfo";
import { useQueryGetMetadata } from "../hooks/query/team/useQueryGetMetadata";
import { useQueryGetFooter } from "../hooks/query/team/useQueryGetFooter";
export default function RootSettingSection({ teamName }: { teamName: string }) {
const { data: blogData } = useQueryTeamInfo({ name: teamName });
const { data: metaData } = useQueryGetMetadata({ team_name: teamName });
const { data: footerData } = useQueryGetFooter({ team_name: teamName });
return (
<div className="flex flex-col gap-7">
<main className="grid grid-cols-2 grid-rows-[auto_auto_auto] gap-6">
{blogData && <BlogSettingSection blogData={blogData} />}
{metaData && <MetadataSection metaData={metaData} />}
{footerData && <FooterSection footerData={footerData} />}
</main>
</div>
);
}CSR을 사용한다면, 다음의 waterfall 구조를 갖는다.
1. |-> Markup (without content)
2. |-> JS
3. |-> Query그러나 SSR을 통해 데이터를 미리 fetch했기 때문에 다음의 waterfall 구조를 갖게되어, 사용자가 더 빠르게 페이지를 볼 수 있다.
1. |-> Markup (with content AND initial data)
2. |-> JS++) prefetchQuery를 사용할 때 선언적 UI 처리
로딩 상태를 처리할 때 useQuery를 사용한다면 다음과 같이 명령형으로 처리한다.
export default function App() {
const { data, isLoading } = useQuery(...);
// 로딩 처리
if (isLoading) {
return <div>Loading...</div>
}
return (
<>
{data && ( ... ) }
</>
)
}useSuspenseQuery를 사용한다면 다음과 같이 선언적으로 처리할 수 있다.
// isLoading을 Suspense로 대체했다.
export default function App() {
return (
<Suspense fallback={<div>Loading...</div>}>
<SuspensedChildComponent />
</Suspense>
)
}
const SuspensedChildComponent = () => {
const { data } = useSuspenseQuery(...);
// render data
return <div>...</div>
}공식 문서에 따르면, Suspense와 함께 prefetch를 사용하기 위한 조건을 다음과 같이 설명한다.
If you want to prefetch together with Suspense, you will have to do things a bit differently. You can’t use useSuspenseQueries to prefetch, since the prefetch would block the component from rendering. You also can not use useQuery for the prefetch, because that wouldn’t start the prefetch until after suspenseful query had resolved. For this scenario, you can use the usePrefetchQuery or the usePrefetchInfiniteQuery hooks available in the library.
prefetch를 하기 위해서 usePrefetchQuery, usePrefetchInfiniteQuery를 사용해야 하고 이는 client component에서만 사용가능한 훅이다.
여기서 든 의문은,
- prefetchQuery, prefetchInfiniteQuery, fetchQuery, fetchInfiniteQuery를 사용하면 안되는 건지
- 예를 들어 prefetchQuery + useSuspenseQuery를 사용했을 때 네트워크 중복 요청을 발생시키는지, Suspense가 동작하지 않는지
그래서 prefetchQuery와 함께 사용해봤다.
export default async function SettingPage({
params,
}: {
params: { teamName: string };
}) {
const { teamName } = params;
await prefetchMetadata({ team_name: teamName });
await prefetchFooter({ team_name: teamName });
return (
<Suspense fallback={<div className="text-7xl font-bold">세팅 로딩중</div>}>
<RootSettingSection teamName={teamName} />
</Suspense>
);
}네트워크 요청을 비교해보니 아래와 같다.
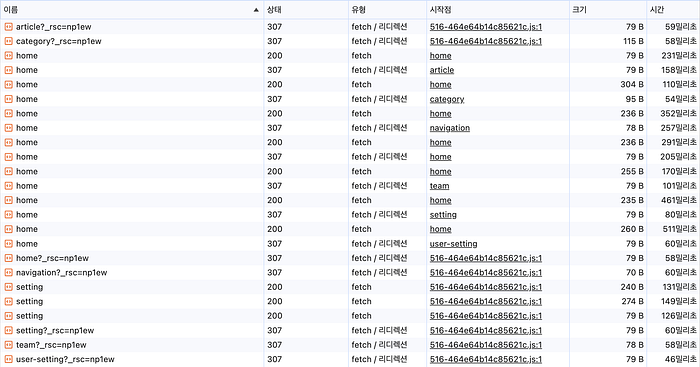
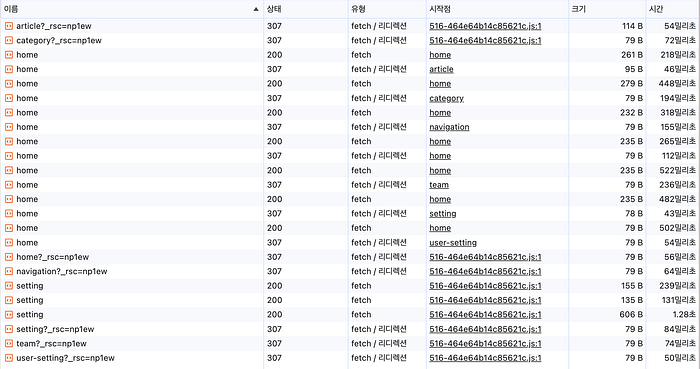
prefetchQuery와 useSuspenseQuery를 함께 사용할 때 중복 네트워크 요청은 발생하지 않고, Suspense도 정상적으로 동작한다.
다만, queryFn에 전달하는 함수가 ‘use server’를 통해 실행되어서 아래의 오류가 발생했다.
Server Functions cannot be called during initial render. This would create a fetch waterfall. Try to use a Server Component to pass data to Client Components instead.
테스트에 사용한 코드는 다음과 같다.
export const useQueryGetFooter = ({ team_name }: GetFooterParam) => {
const { data, error, isPending } = useSuspenseQuery({
queryKey: ["footer", team_name],
queryFn: () => getFooter({ team_name }),
});
if (error) throw error;
return { data, isPending };
};'use server';
import prisma from "@plx/db/client";
// queryFn에 전달되는 함수, supabase에 접근할 때 prisma를 사용한다.
export const getFooter = async ({ team_name }: GetFooterParam) => {
const response = await prisma.footer.findUnique({
where: {
team_name,
},
});
return parseBigInt(response);
};(prisma는 브라우저 환경에서 접근할 수 없어서 'use server’;가 필요하다.)
이는 서버에서 동작하는 route handler로 해결할 수 있다.
// route handler가 내부 로직을 처리하도록 변경한다.
export const getFooter = async ({ team_name }: GetFooterParam) => {
const { data } = await instance(`/api/footer/${team_name}`);
return data;
};
// api/footer/[name]/route.ts
export async function GET(
request: NextRequest,
{ params }: { params: { name: string } }
) {
// 기존 getFooter의 로직이 여기서 처리된다.
const response = await prisma.footer.findUnique({
where: {
team_name: params.name,
},
});
const data = parseBigInt(response);
return NextResponse.json({ data });
}결론은,
- prefetchQuery는 useSuspenseQuery와 함께 사용해도 된다. Suspense도 정상적으로 동작한다.
- 다만, queryFn에 전달되는 함수는 ‘use server’로 처리하면 안된다.
- 만약, prisma 같이 브라우저 환경에서 접근이 불가능해 ‘use server’가 불가피하다면, 내부 로직을 route handler로 처리하고 함수의 ‘use server’는 제거한다.
결과
/home 라우트 기준으로 첫 페이지 로딩 속도를 아래와 같이 단축했다.
8.64s -> 347 ms (단, 수정 후 소요 시간은 편차가 존재한다. 최대 1.x s)


마무리
- 속도를 더 개선할 방법은, Prisma Accelerate를 사용하면 되는데 Supabase를 지원하지 않아서 적용은 못했다.
- 백엔드 Table 구조를 더 탄탄하게 설계해야 한다. (+ 인덱싱)
- server action은 병렬 처리가 되지 않는다. 이는 병렬 처리를 지원하는 useQueries, useSuspenseQueries와 함께 사용할 시 의도한 대로 동작하지 않음을 의미한다.
- API 호출이 필수적인 서비스는, waterfall을 고려해서 좋은 로딩 속도를 설계해야 한다. (결국, API 호출을 잘 다뤄서… 빠르게 서비스를 제공해야 한다)
